


2·
3 days agoCould you please tell me why you chose kobold.cpp over llama.cpp? I only ever used llama.cpp so I’d like to hear from the other side!
I really like the idea of letting an LLM perform too calls into middle of the generation.
Like, we instruct the LLM to Say what it will do, then to put the tool call into <tool></tool> tags. Then we could set </tool> as a stop keyword and insert the results into it’s message.
I have tries this before, but it tends to not believe what is in its own message. It tends to see the output of the tool cal and go Don't believe what I just said, I made that up, even though LLMs are infamous for hallucinating…

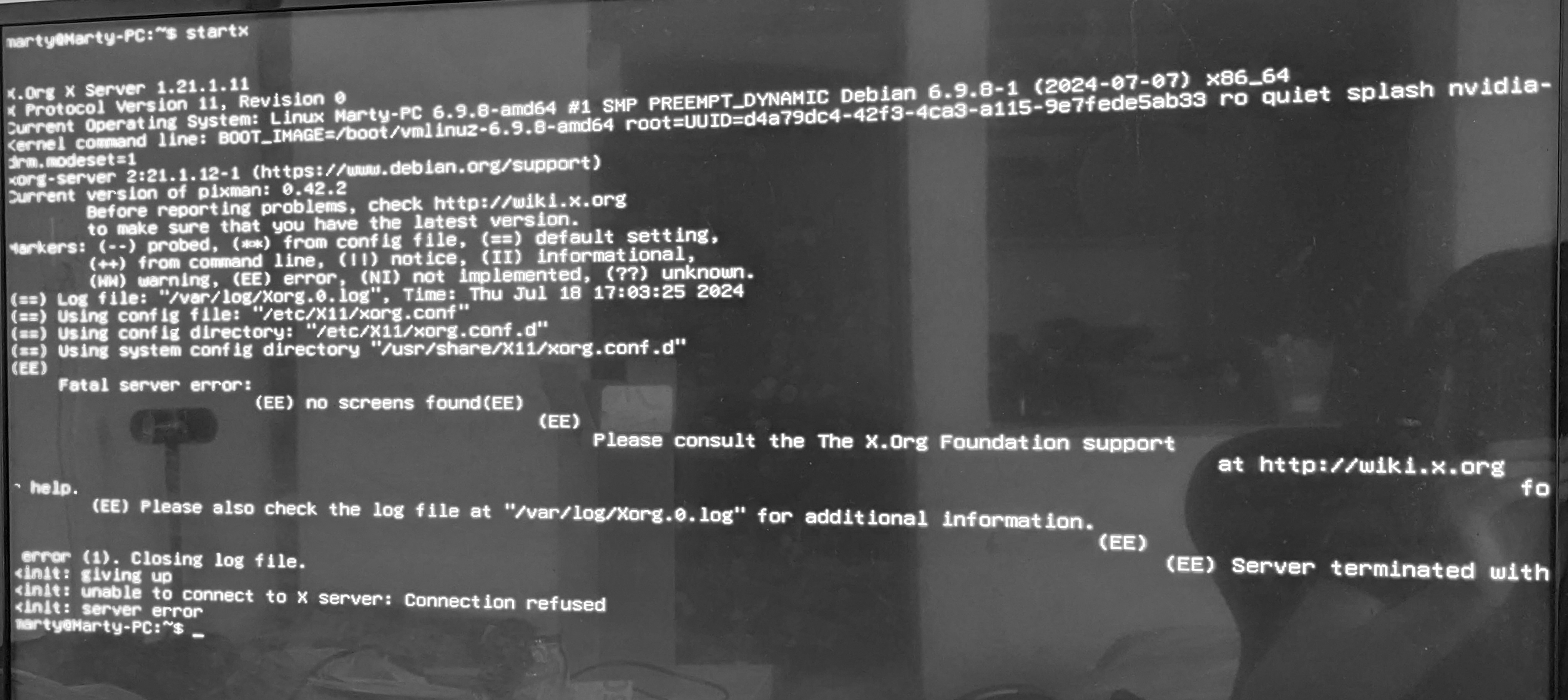{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
This prefix feature is already in Open Web UI! There is the “Playground”, which lets you define any kind of conversation and also let it continue a message you started writing for it. The playground is really useful.
What exactly do you mean by “draft models”? I have never heard of that speculative decoding thing…